
Msg 성장일기
테이블 액세스 최소화 본문
[ 인덱스 ROWID는 논리적주소 ]
└ ROWID는 디스크 상에서 테이블 레코드를 찾아가기 위한 위치 정보를 담았기에 논리적 주소이다.
└ 인덱스 ROWID는 포인터가 아니다. (*포인터: 메모리 주소값을 담는 변수)

└ ROWID가 가리키는 테이블 블록을 버퍼캐시에서 먼저 찾아보고(위 그림 점선), 못 찾을 때만 디스크에서 블록을 읽는다. 물론 버퍼캐시에서 적재한 후에 읽는다.
[ 인덱스 클러스터링 팩터(CF) ]
└ 특정 컬럼을 기준으로 같은 값을 갖는 데이터가 서로 모여있는 정도를 의미한다.
└ CF가 좋은 컬럼에 생성한 인덱스는 검색 효율이 매우 좋다. 이는 테이블 액세스량에 비해 블록I/O가 적게 발생함을 의미한다. 물리적으로 데이터가 근접해 있으면 찾는 속도가 빠르다.

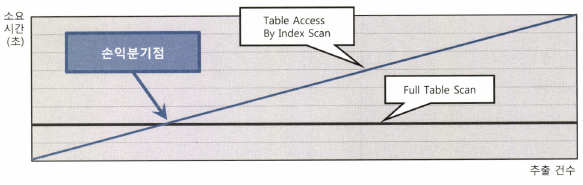
└ 읽어야 할 데이터가 일정량을 넘는 수간, 테이블 전체를 스캔하는 것보다 오히려 느려진다.
[ 인덱스를 이용한 테이블 액세스가 Table Full Scan보다 더 느려지게 만드는 가장 핵심적인 두가지 요인 ]
└ Table Full Scan은 시퀀셜 액세스인 반면, 인덱스 ROWID를 이용한 테이블 액세스는 랜덤 액세스 방식이다.
└ Table Full Scan은 Multiblock I/O인 반면, 인덱스 ROWID를 이용한 테이블 액세스는 Single Block I/O 방식이다.
[ 배치 프로그램 튜닝 ]
└ 대량 데이터를 읽고 갱신하는 배치 프로그램은 항상 전체범위 처리 기준으로 튜닝해야한다。
└ 대량 데이터를 빠르게 처리하려면, 인덱스와 NL조인보다 Full Scan과 해시조인이 유리하다.
insert into 고객_임시
select /*+ full(c) full(h) index_ffs(m.고객변경이력)
ordered no_merge(m) use_hash(m) use_hash(h) */
c.고객번호, c.고객명, h.전화번호, h.주소, h.상태코드, h.변경일시
from 고객 c
,(select 고객번호, max(변경일시) 최종변경일
from 고객변경이력
where 변경일시 >= trunc(add_months(sysdate, -12), 'mm')
and 변경일시 < trunc(sysdate, 'mm')
group by 고객번호 ) m
, 고객변경이력 h
where c.고객구분코드= 'A001'
and m.고객번호 = c.고객번호
and h.고객번호 = m.고객번호
and h.변경일시 = m.최종변경일시└ 고객구분코드가 'A001'인 고객의 최근 1년 이내 변경 이력 중 전월 말일 데이터를 읽어 고객_임시 테이블을 입력한 코드
└ Full Scan과 해시조인을 사용하여 효과적이다.
[ 테이블 액세스 최소화를 위한 튜닝 기법 ]
1) 인덱스 컬럼 추가
2) 인덱스만 읽고 처리
└ 테이블 랜덤 액세스가 많아도 필터 조건에 의해 버려지는 레코드가 거의 없을 경우의 튜닝 방법
└ 인덱스만 읽어서 처리하는 쿼리를 Covered 쿼리라고 부르고 그 쿼리에 사용한 인덱스를 Covered 인덱스라고 한다.
*include 인덱스
└ 인덱스 키 외에 미리 지정한 컬럼을 리프 레벨에 함께 저장하는 기능
└ 순전히 테이블 랜덤 액세스를 줄이는 용도로 개발됐다.
[ 인덱스 구조 테이블 ]
└ 랜덤 액세스가 아예 발생하지 않도록 테이블을 인덱스 구조로 생성, 오라클은 이를 IOT(index-Organized Table)이라 하고, MS-SQL Server는 클러스터형 인덱스라고 한다.
└ IOT는 ROWID를 갖는 일반 인덱스와 달리 그 자리에 테이블 데이터를 갖는다. 즉, 테이블 블록에 있어야 할 데이터를 인덱스 리프 블록에 모두 저장하고 있다. '인덱스 리프 블록 = 데이터 블록'
└ IOT는 인위적으로 클러스터링 팩터를 좋게 만든다.
[클러스터 테이블]
클러스터 테이블은 인덱스 클러스터와 해시 클러스터 두 가지가 있다.
1)인덱스 클러스터 : 클러스터 키값이 같은 레코드를 한 블록에 모아서 저장하는 구조
#클러스터 생성
create cluster c_dept# (deptno number(2)) index;
#인덱스 정의
create index c_dept#_idx on cluster c_dept#;
#클러스터 테이블 생성
create table dept(
deptno number(2) not null
, dname varchar2(14) not null
, loc varchar2(13) )
cluster c_dept#( deptno );

2)해시 클러스터 : 인덱스를 사용하지 않고 해시 알고리즘을 사용해 클러스터를 찾아간다.
#클러스터 생성
create cluster c_dept# ( deptno number(2) ) hashkeys 4;
#클러스터 테이블 생성
create table dept(
deptno number(2) not null
, dname varchar2(14) not null
, loc varchar2(13)
cluster c_dept#( deptno );

출처: 개발자를 위한 SQL 튜닝 입문서 친절한 SQL 튜닝
'study_SQL > 친절한 SQL 튜닝' 카테고리의 다른 글
| 인덱스 스캔 효율화 (0) | 2023.06.14 |
|---|---|
| 부분범위 처리 활용 (0) | 2023.06.14 |
| 인덱스 확장기능 사용법 (1) | 2023.06.14 |
| 인덱스 기본 (0) | 2023.06.13 |
| SQL 처리과정과 I/O (0) | 2023.06.13 |


